
GCP, Terraform, CD & Bitbucket

I have recently been working with a company, let’s call them AA regularly delivers applications that deliver an intelligent interpretation of data using the Google Cloud Platform. AA Uses APIs to read data that gets fed into pipelines, the data is then interpreted by Machine Learning and Language Analysis before it is delivered to data storage, and then displayed using dashboards that read the data source. AA utilizes the skills of many developers. The solutions are developed using “the language that makes sense”, so it is not uncommon for solutions to have some Python, and some Golang. Databases will be a combination of NoSQL, MySQL, and BigQuery. There are queues that are used to flatten out resource usage. AA regularly deploys to many different environments.
How do we manage deployments?
There are so many disparate technologies that have to come together to form a solution. There are naming conventions that must be adhered to. There are potentially many programming languages in a single solution. There is a list of APIs that need to be enabled as long as my arm. The solution needs to have a database instance spun up. There will be schemes that need to be corrected. Any small error in the connecting technologies will result in the failure of a part of the system.
Terraform to the rescue?

There has to be a better way! Terraform is a programming language/system that delivers the whole system configuration as code. No need for the entry of commands through the command line. No need for the click of options through the web console. Everything can be done within the Terraform programming language. Terraform keeps the current state of the machine that it is interacting with a state file and only applies the programming configuration if the system needs it. It determines if there is a need by checking if there is a difference between the configuration code and the machine state.
Now the problems start. Terraform is not pure. Only some of the Google Cloud Functions operations are available in the terraform libraries. and the libraries sometimes have some “shortcomings”. So now we start to get into problems because we need some scripts run in conjunction with Terraform. We have to be careful with changing the state somewhere where Terraform will not be able to resolve it automatically. I’ll get back to this because the next problem needs to be introduced.
Multiple Instances
Terraform works great if we program it for just one instance. But we are deploying this to multiple Google Cloud Platform environments. We have a Dev instance (that gets polluted by developer testing), Staging instances, and Production. The production instances are of such high security that even the developers do not have access to them. So how do we do DevOps when developers cannot see the environment that they are deploying to?
The development team needs to write multiple Terraform scripts for all of the different environments. And have such high confidence in the deployment that it works sight unseen and with no opportunity to correct errors. How can we achieve this?
Hello Bitbucket Pipelines

With a good branching strategy and the use of Bitbucket Pipelines, we get the level of automation that we need for deployment. And because of the ability of Bitbucket to have protected environment variables, the pipelines can be set up to deploy securely.
Now we can have Developer Branches and Deployment branches. Developers can check into the development branch, the pipeline will run automatically to deploy and redeploy to the developers’ test environment. So far so good. But what about the duplication of the code for the different environments? How do you create and maintain multiple terraform scripts for deploying to dev, test, and production environments? And what happens when you want to deliver to a second prod environment, a third, etc?
Selectable Configuration Variables
Terraform allows for the configuration to be passed in as JSON variables. In fact, most of Terraform can be driven by variables. In most programming languages, concepts can be abstracted. This is done with functions in structural, and methods in object-oriented programming. Terraform has a similar sort of abstraction. The code below calls a sub-terraform script and passes in the variables..
<code>module "pubsub_topic_tweets" {
source = "./google_pubsub_topic"
pubsub_topic_name = var.pubsub_topic_tweets
}</code>
In the code above you can see that this calls a standard Terraform script google_pubsub_topic to set up a PubSub Queue. This style of Terraform programming really makes use of code blocks, reduces cut-and-paste errors, and standardizes the way elements are set up. This last sentence is very important. The use of these code blocks::
- Reuses code
- Reduces cut-and-paste errors
- Standardizes the way that GCP elements are creates
We had a really smart developer come up with this, and my jaw dropped. Machine setup code that looks like a programming language function.
Now that we have a variable-driven approach we need to set up and select the variables.
The Environment Name decides the way
In our first trial of setting this up, we use “Dev” and “Test” for the names of the pipelines in the Bitbucket. This was a complete mess because we were constantly trying to map the google cloud platform name to the different pipelines. Then we decided that since the Google Cloud Platform was immutable we would name our pipelines after the environment. Then when we deployed to a new environment it would be a simple matter of following the existing pattern.
Everything then fell into place. The documentation was reduced. Adding to the environments and pipelines became intuitive. Developers that had not worked on the project were able to see the pattern quickly and then implement a new platform.
You can see here that the naming convention is the same as the name of the Google Cloud environment. So we were excited, we were pumped. What could we do next to reduce copy-paste? How could we improve our code further?
Terraform uses a variable.tf file to “declare” all the variables that would be used with the creation of the system. Our first attempt was to declare all the variables and then create a massive config.tfvars.json to set them up.
This would set up the name of the PubSubs, and the name of the cloud functions. So we had a massive JSON config and due to the nature of JSON (no variable substitution), we again had massive duplication of code. The answer came from a less experienced Terraform developer who could not accept duplication.
“Default” is little known but so useful
Terraform has a file variable.tf that allows you to declare all the variables that will be used. It has a little-known feature (ok, maybe it is well known, but we did not know about it) called Default. This looks like the following:
<code># Pubsub Topics
variable "pubsub_topic_searches" {
type = string
default = "searches20"
}
variable "pubsub_topic_tweets" {
type = string
default = "tweets20"
}</code>
Now we can set up all the common elements that are the same between all deployments declared in our variables.tf as a default. Then we can remove 90% of our JSON and just keep the stuff that is different. What a refactor. It made the author so happy I did the programmer “happy dance” (in the privacy of my own office of course).
Terraform “Undocumented Features”
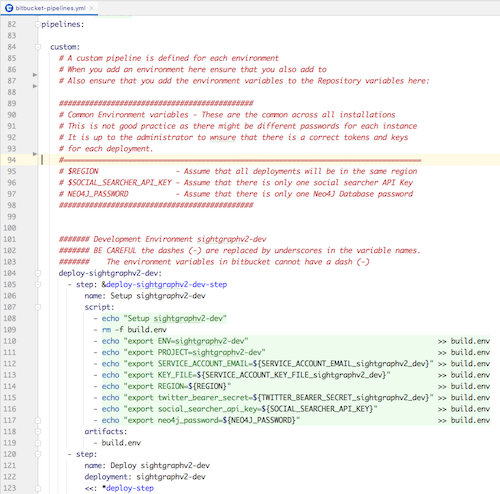
The Pipeline feature of Bitbucket is very powerful. It basically sets up a Docker machine and runs scripts. This meant that we could code for different situations, and handle some of the Terraform shortcomings since we get a chicken-and-egg situation with the Terraform state file. We were able to use GCP utility functions to check to see if the storage bucket existed. If it didn’t exist we knew that it was the first run and could set some environment variables accordingly. In the script to we could set up the APIs (something that is not done well in Terraform) so we were able to utilise the strengths of Terraform, and the strengths of bash scripting
Below is an example of the script that we use. Here you can see that we are using gsutil to get the storage bucket state and passing environment variables in on the Terraform Command line.

Within the scripts, we can use the gcloud command-line call to set up all the APIs that we need. This is all possible because we can download the Google Cloud Platform tools and install them in the Docker instance.
<code>echo "Starting…" gcloud services enable appengine.googleapis.com gcloud services enable bigquery.googleapis.com gcloud services enable cloudbuild.googleapis.com</code>
Putting it all together
Putting this all together, we have the best of ALL worlds. Best automatic and manual deployment. Best of Terraform for automated machine deployment, and Bitbucket Pipelines for source control with DevOps. We have maintained an amazing level of security. We have utilised the best programming language for solving the computational elements of the problem. We have achieved a level of reliability on a machine/solution that has a staggering number of moving parts.
What happens when a deployment works perfectly…
